
MLCommons has released results for its MLPerf 5.0 training benchmark. Debuting in this edition are results for AMD MI300X and MI325X GPUs and for the Google Trillium TPU, enabling limited comparisons with Nvidia Blackwell and Hopper GPUs. For large language model (LLM) pretraining, the new MLPerf release replaces the previous version’s GPT-3 with Llama 3.1-405B.
MLPerf LLM Update
- Llama 3.1-405B is a bigger model than the previous GPT-3 test and incorporates new algorithms, making it more representative of LLM pretraining workloads.
- As with the GPT-3 test, the new one doesn’t train the model from scratch but instead between checkpoints, which reduces execution time.
- The benchmark replaces Llama’s tokenizer with the Mixtral 8×22B one because MLCommons expected the Llama one would’ve converged by the starting checkpoint.
Submissions
- Twenty organizations submitted results. Most, however, employ Nvidia GPUs.
- Systems/boards employed include several accelerators: AMD MI300X, AMD MI325X, Nvidia Blackwell (B200 and GB200), Nvidia Hopper (H100 and H200), and Google Trillium. Also included were a few desktop GPUs: Nvidia RTX A5000, Nvidia RTX 4090, and AMD Radeon RX 7900 XTX.
- Although it’s a data-center accelerator, Trillium isn’t comparable to merchant GPUs; moreover, Google only supplied Stable Diffusion results. Therefore, we have no conclusions other than noting Trillium delivers greater throughput per chip than its predecessor, the TPU v5p.
- Similarly, our focus is on data-center chips, and the desktop GPUs are an odd assortment. We decline to compare their results.
AMD
- AMD submitted results for both the MI325X and the MI300X.
- The company only tested these GPUs on the Llama 2-70B fine-tuning test and only tested a single eight-GPU node. Other companies’ submissions for AMD GPUs also only ran this single test.
- On this test, the MI325X performed slightly better than the Nvidia H200 in a similar 8× configuration. The MI300X was slightly worse than the Nvidia H100. (We went back to the previous MLPerf edition to get the Nvidia data on this test.)
- Dell, MangoBoost, and Oracle Cloud also submitted MI300X results and approximately matched AMD’s score in an 8× GPU configuration.
- GigaComputing, Quanta Cloud, and Supermicro did the same with the MI325X and similarly validated AMD’s score.
- MangoBoost also tested the MI300X in two- and four-node (16 and 32-GPU) configurations. Scaling was mediocre on this workload with this hardware. The 32-GPU cluster was about three times faster than the 8-GPU one, as Figure 1 shows.
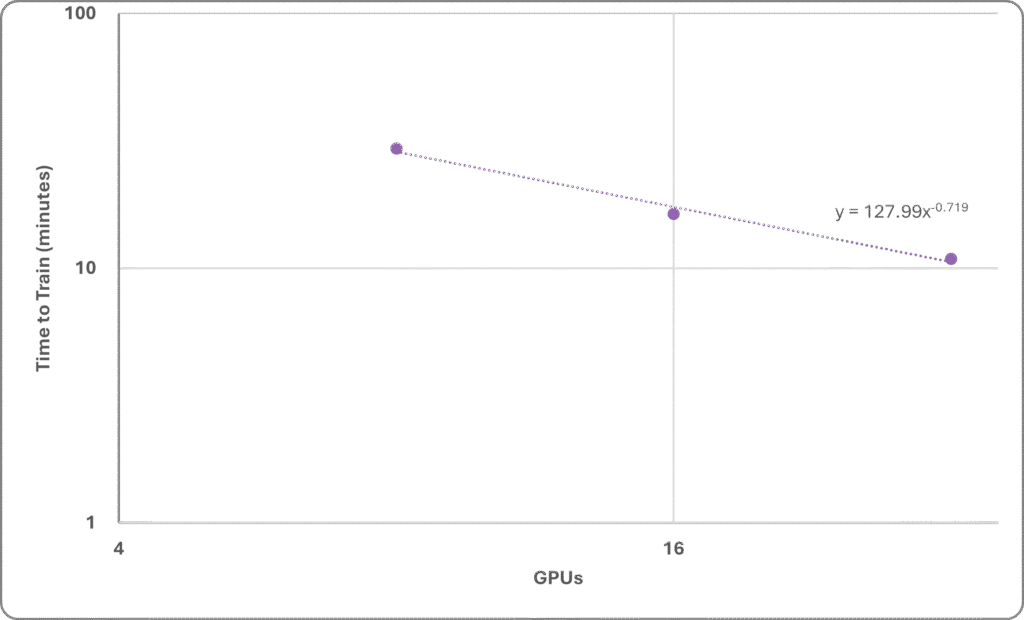
Figure 1. AMD MI300X scaling. (Data source: MangoBoost via MLCommons)
Nvidia
- Numerous companies submitted results for Nvidia-based systems, employing a variety of hardware configurations and software frameworks.
- Lenovo provided the only entry on the MLPerf power benchmark, employing an 8× Nvidia GB200 system.
- Nvidia GPUs are the only chips to have submissions for every MLPerf test.
- Importantly, Nvidia GPUs are the only chips to execute the Llama 3.1-405B pretraining test, reflecting the company’s dominance among companies developing the largest LLMs.
- Nvidia featured its cloud service training Llama 3.1-405B with 512–8,192 Hopper H100 GPUs.
- Cloud GPU provider CoreWeave employed Nvidia NVL72 systems to generate results on this test using 512–8,192 Blackwell GPUs.
- Hopper and Blackwell scaled well, as Figure 2 shows.
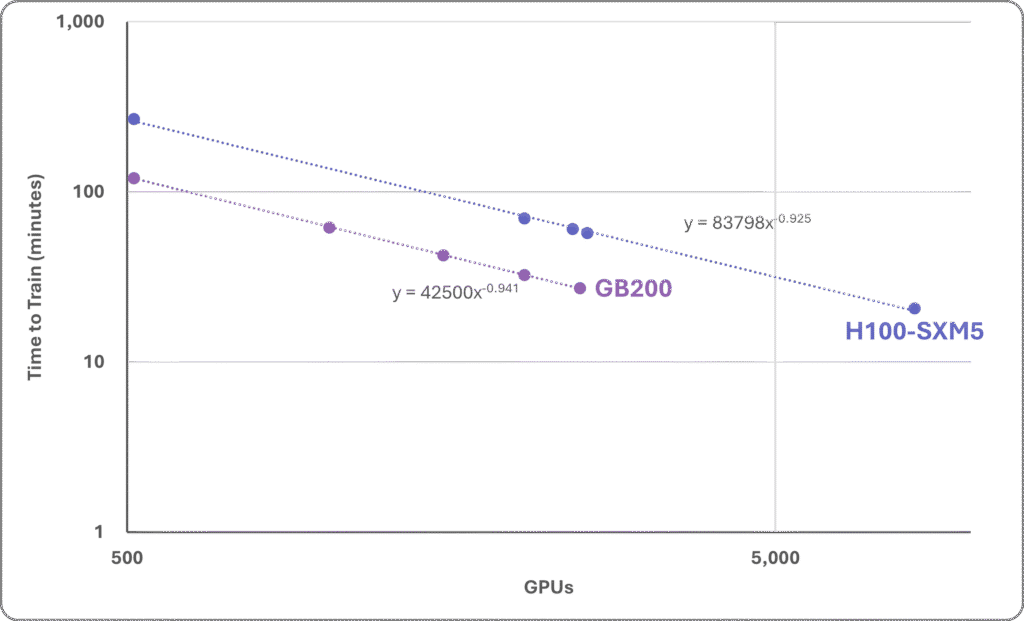
Figure 2. Nvidia H100 and GB200 scaling. (Data sources: Nvidia and CoreWeave via MLCommons)
Bottom Line
The semiannual MLPerf faceoffs are an opportunity for chip suppliers and partners to demonstrate their AI accelerators. Model training is an important AI workload—without training, there would be nothing to perform inferencing—and companies training massive models spend billions of dollars annually on AI accelerators. Few suppliers, however, show up to challenge Nvidia with real results.
Those that do appear can’t match its per-chip throughput, and only Google hints at an ability to scale out as well. AMD is the best-positioned merchant supplier to challenge Nvidia’s hegemony. Its offerings rival Team Green’s previous generation but haven’t shown the same ability to scale and tackle big jobs like Llama 3.1-405B.
Scaling is generally an issue, however. At the chip level, Blackwell proves to be about twice as fast as Hopper on Llama 3.1-405B training—a bit worse than we expected. At the system level, near-linear scaling is impressive. But once the number of GPUs is in the thousands, the sublinearity compounds and throughput only slowly ratchets up for each added node, even for the best systems.