Arm has disclosed its first Lumex-branded licensable designs (IP) for mobile clients. Predominantly targeting smartphones, the Lumex platform includes four CPU performance tiers and is the company’s first implementation of Scalable Matrix Extensions (SME2) for AI processing and other matrix-math workloads. Alongside the new CPUs, Arm has updated its Mali GPU, adding ray-tracing acceleration. New system IP raises performance and power efficiency for chips employing the Lumex and Mali designs.
Arm CPUs had employed the Cortex brand for all segments other than infrastructure, where it used Neoverse. In May, the company introduced new names for different segments, as Table 1 shows. How the company will replace the -A, -R, and -M suffixes for Auto and Industrial is undisclosed but is moot for Mobile, which covers only A-class CPUs.
Table 1. Arm CPU brand names.
In addition to a new name, Arm has updated its designations for individual products, employing Ultra, Pro, and Nano in place of Cortex-X, Cortex-A700, and Cortex-A500. On the GPU side, Mali Ultra replaces the ironically short-lived Immortalis brand for flagship configurations integrating 10 or more cores and accelerated ray tracing; Premium and Pro designate those with up to 9 and 5 cores, respectively. The current CPU crop is called the C1, and the GPU is the G1. We presume next year’s IP will be the C2 and G2. Arm also expanded the CPU lineup to include a fourth Premium tier situated between Ultra and Pro, as Figure 1 shows.
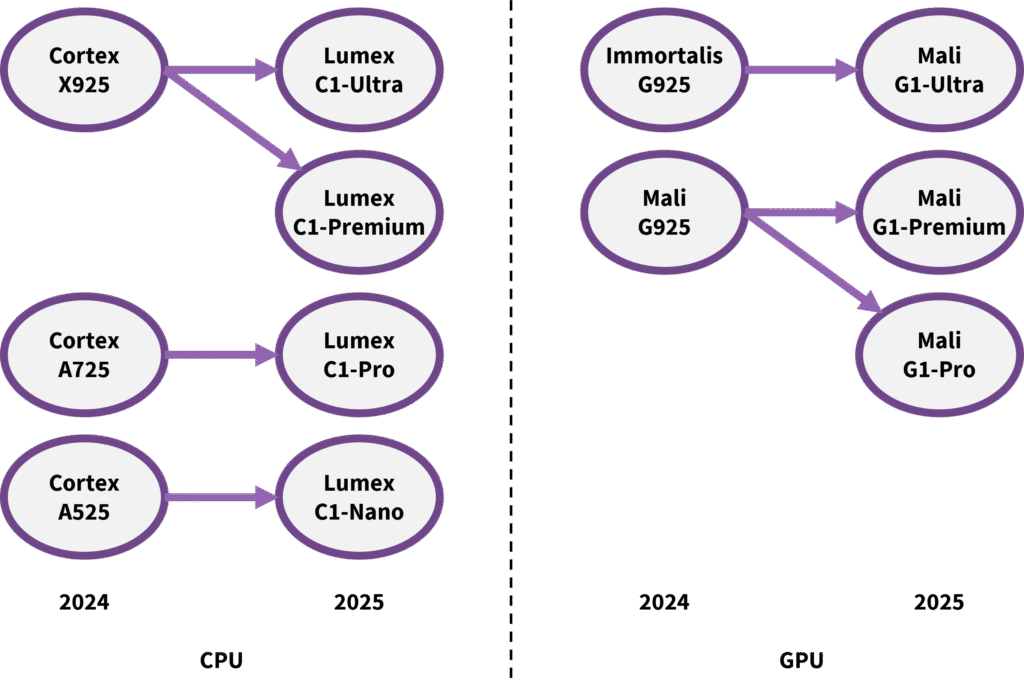
Figure 1. Arm Lumex and Mali rebranding and product tiers.
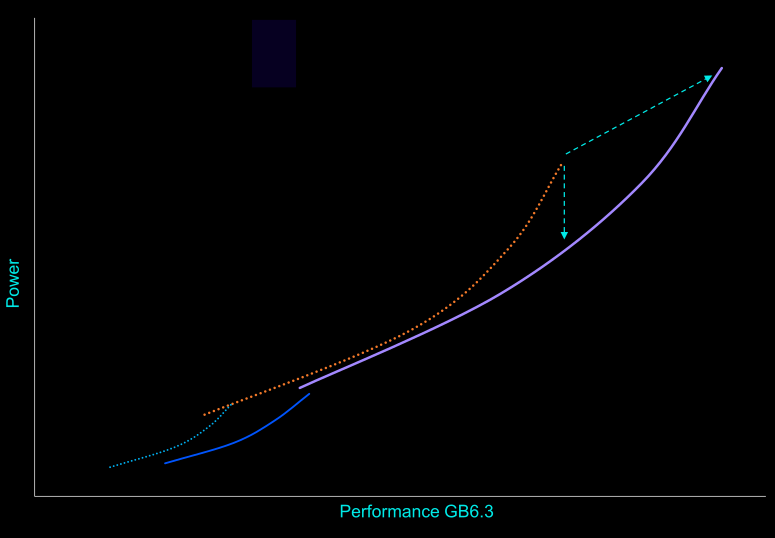
Smartphones employing Lumex-based chips are due by the end of the year. Arm reports that a flagship Lumex CPU cluster will be 15% faster and 12% lower power than the comparable 2024 cluster. Software that takes advantage of SME2 will see the biggest uplift. For example, the new extensions were among the factors helping Lumex score 45% higher on the Geekbench 6.3 multithreading benchmark. A 14-core Mali G1-Ultra is 20% faster than a similar Immortalis-G925 from last year.
Lumex C1 CPUs are Arm’s First to Implement SME2
The new Lumex CPUs achieve greater per-cycle throughput, owing in part to adding SME2 matrix extensions. Last year, we saw Geekbench scores increase for the Cortex-X925 over the earlier Cortex-X4, helped by its additional SVE2 units. This year, the Geekbench 6.3 subtests that SME2 significantly speeds up are pulling up the C1’s overall score.
Although SME2 is Arm’s second iteration of its scalable matrix extensions, it’s the first that the company has implemented in its CPUs. Covering various matrix-math operations, SME2 also includes scatter-gather and other ancillary functions. To amortize the area required for SME2, Arm integrates only one or two units per CPU cluster. (Its exemplary design with two Ultras and six Pros has two SME2 units.) An arbitrator multiplexes threads’ access to the shared resource. The initial implementations employ 512-bit vectors, resulting in an SME2 unit holding about 4 KB of state.
By contrast, IBM overlays matrices on its vector registers for the extensions that Power11 implements, conserving area but also restricting performance. Intel integrates its AMX unit in each matrix-enhanced CPU, raising performance potential but adding significant area for an uncommon operation.
SME2 Enablement
Arm laid the groundwork for SME2 adoption last year when it introduced Kleidi, a software library targeting AI and computer vision (CV). Kleidi routines employ SVE2 and SME2 when a CPU supports them. They’re lightweight and integrate into AI and CV frameworks, enabling developers employing those frameworks to benefit from features such as SME2 without explicitly coding for them.
The C1 Cores are Arm’s First Lumex CPUs
Lumex C1-Ultra and C1-Premium
The Lumex C1 Premium and C1 Ultra are different configurations of a common microarchitecture based on that of the past two Cortex-X generations. Like the Cortex-X925 disclosed last year, the Ultra integrates six 128-bit SVE2 (SIMD vector) pipelines, but the Premium reduces this to two to conserve area. For the same reason, the Premium defaults to a 1 MB L2 cache compared with 2 MB for the Ultra; 3 MB is the maximum configuration.
Arm rates the Ultra at 4.1 GHz compared with 3.6 GHz for X925, although smartphone processors might not run at this peak frequency. The company has updated the X925 design, but the microarchitecture is similar. It’s among the widest (if not the widest) ever commercialized, with 10 decoders and 21 execution ports, as Figure 2 shows.
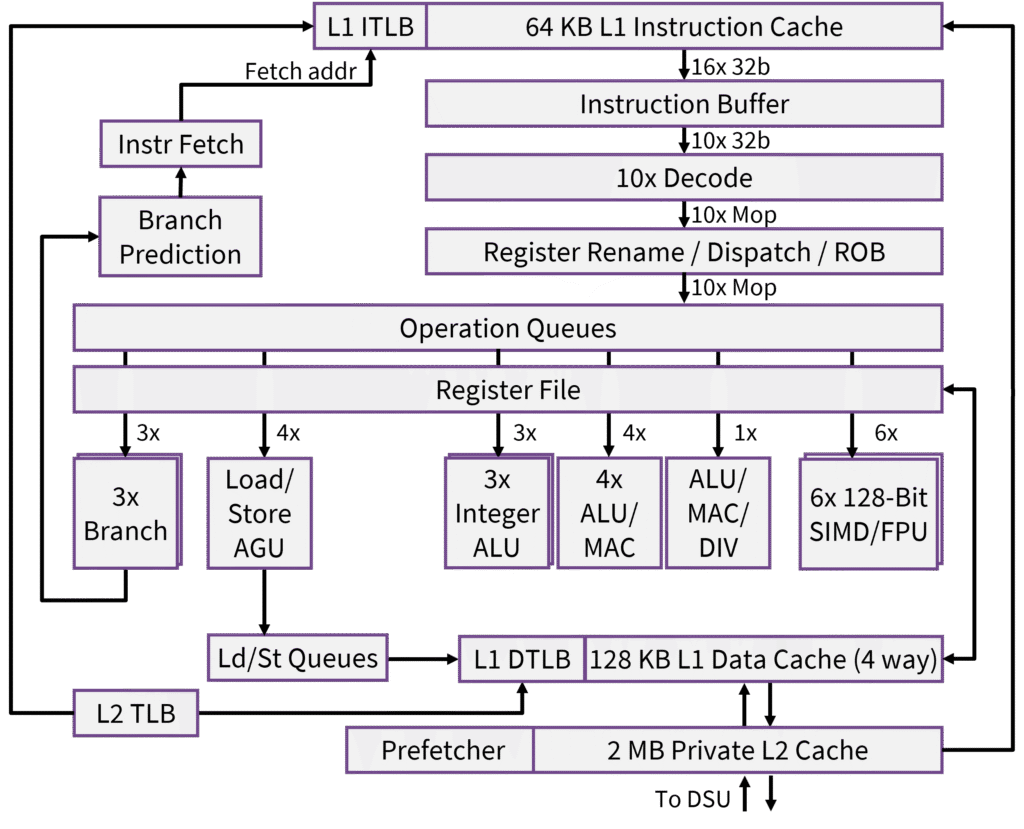
Figure 2. Arm Lumex C1-Ultra microarchitecture.
In addition to adding SME2 support, Arm revised the design to raise instruction throughput (IPC). In the front end, the data path from the L1 cache to the instruction buffer is 16 instructions wide, up from 12. The CPU handles code with frequent control-flow changes (branches) better, resulting in more instructions proceeding to the back end per cycle in these cases. Branch-prediction accuracy has also improved, with mispredictions declining by about 4% on average and by much more on some code.
The out-of-order window, which had been huge, is now gargantuan at a maximum of 2,000 operations in flight. (By comparison, the AMD Zen 5 CPU can track fewer than 500.) Arm has an unusual reorder technology that can track multiple consecutive instructions instead of individual ones, which helps boost the number that can be in flight. Additionally, more instructions can be eliminated—that is, executed—in the front end, such as immediate moves, freeing back-end resources.
In the back end, the data cache has doubled to 128 KB, and the data prefetcher can handle more cases. Arm has sped up various long-latency operations, such as shift and encryption operations. Back-end stalls are down 15% or more on some code and about 5% on average, translating directly to higher IPC. Factoring in its faster clock rate, the added SME2 instructions, and the higher IPC, the C1-Ultra’s peak performance as measured on Geekbench 6.3 is 25% greater than that of the Cortex-X925.
Lumex C1-Pro
The C1 Pro refreshes the Arm Cortex-A725 design. Instruction throughput (IPC) increases, although the company has withheld specific data for a standard benchmark such as Geekbench or SpecInt. However, it reports that the C1 Pro delivers an 11% greater Geekbench 6.3 score at the same power. On a few select non-SME2 workloads, IPC increases by 10%–16%, according to Arm.
The C1 Pro’s IPC gains come from a combination of factors. In the front end, these include bigger branch-target buffers, a larger first-level instruction TLB, and better branch prediction. Compared with the A725, the misprediction rate decreases by a median of 4.1% on a range of tests and by 80% or more in some instances. Because of an incorrect prediction’s performance impact, mitigating a few bad cases can significantly raise IPC. To conserve power, the Pro does not act on low-confidence branch predictions by default, whereas the performance-focused Ultra does. In the back end, Arm reduced the second-level TLB’s latency and improved data prefetching. Back-end stalls, as a result, improved by a median of 3.5% on a range of tests, as Figure 3 shows.
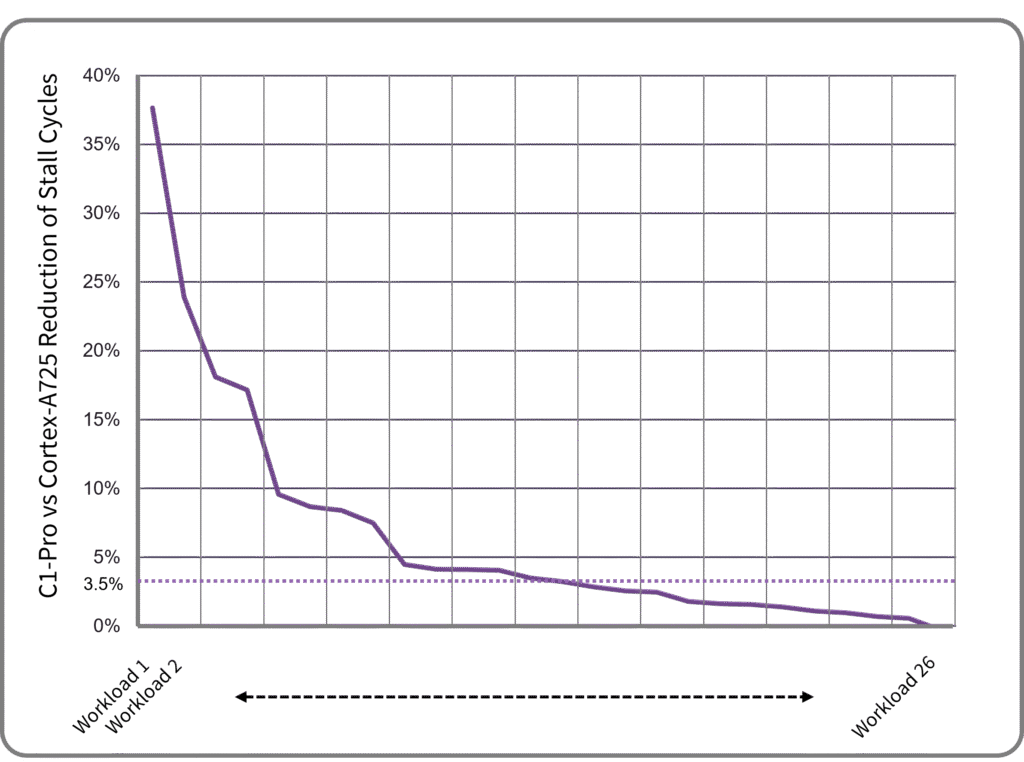
Figure 3. Arm C1-Pro stall-cycle reduction on various workloads.
As it did with the Cortex-A720, Arm offers the C1 Pro in an area-optimized configuration sized to fit in the same footprint as the Cortex-A78, excluding SME2 support. Throughput is about 5% greater than the comparable A720. Customers can optionally add SME2. The configuration is for customers seeking an upgrade from the A78 or to conserve die area.
Lumex C1-Nano
The C1-Nano similarly builds on the Cortex-A520, updating branch prediction and prefetchers. As with its predecessors, a Nano pair can share an SVE2 unit and L2 cache to save die area. The Nano also supports SME2, which is mainly implemented at the cluster level. While the C1-Nano is an in-order machine like its predecessor, it decouples the front and back ends. Unshackled, the front end can prefetch instructions earlier, enabling the Nano to mitigate stalls from cache misses. Branch-prediction accuracy and, in the back end, data prefetching have improved, too. SpecInt2017 performance is 5.5% higher than the A520, but the core is only 2% larger. Clock gating has been enhanced, contributing to the Nano raising power efficiency by 26%.
Mali G1 Doubles Ray-Tracing Throughput
In the new Mali G1, ray tracing accounts for most architectural changes. In addition to intersection tests as before, the G1 accelerates traversing the boundary-volume hierarchy (BVH). In brief, to process rays efficiently, each triangle in a scene resides in a box, and boxes nest inside bigger boxes. This matryoshka-like structure of boxes is called the BVH. To determine which triangles a ray strikes, the GPU checks if it intersects the outermost boxes. If it doesn’t, then many triangles can be skipped, saving time and energy. If it does, then the testing process repeats for the boxes inside.
Shader cores can’t efficiently perform these intersection tests, so they’re the first thing GPU implementations offload to accelerate ray tracing. They aren’t great at traversing the BVH, either, making this the second-priority task to automate, as the Mali G1 does. Combined with other enhancements, the traversal acceleration doubles the ray-tracing throughput of the Immortalis-G925. Performance on the Lumilings benchmark, which includes ray tracing, increases by 40%.
Future acceleration could include sorting rays so that similar ones are processed together, raising cache hit rates. However, Arm hasn’t indicated it’s going in this direction. It has disclosed that the next-generation GPU due in 2026 will include Arm’s neural technology. It’s synergistic with ray tracing; it can denoise ray-traced scenes or upscale/interpolate them.
Games and AI Speed Up by 20%
The G1 additionally includes several enhancements to speed up rasterization. New logic detects dependencies among regions, permitting a degree of overlap between rendering passes provided they aren’t operating on the same region. The G1 also doubles the number of uniform registers, which hold constant values for shader programs. Additionally, Arm revamped the network connecting GPU resources, adding a second, parallel network to double data throughput, reduce congestion, and double the number of L2 cache slices. All told, Arm expects gaming performance to increase by 20%. Throughput on AI workloads should climb by a similar amount, owing primarily to the G1 adding FP16 (but not BF16) matrix-multiplication hardware and raising throughput compared with FP32 operations by two times.
Like the earlier G925, the G1 implements Arm’s fifth-generation GPU architecture, which is similar to the previous Valhall architecture. At its heart, the design has a fused multiply-add (FMA) engine that executes 16-thread warps, where each thread completes one 32-bit or two 16-bit operations per cycle. Instead of integrating a matrix engine, the GPU handles matrix operations in the FMA pipeline. Each shader core has 16 FMAs, as Figure 4 shows, along with other hardware, clustered in a function-unit hierarchy.

Figure 4. Simplified diagram of Arm’s fifth-generation GPU architecture.
Lumex System IP Sees Significant Upgrade
Alongside the new CPU and GPU designs, Arm is launching new system IP. The Lumex SI L1 system interconnect integrates functions previously handled by the company’s coherent and network-on-chip (NoC) interconnects (e.g., the CI-700 and NI-700). The SI L1 provides coherency, integrates the system-level cache (SLC), implements memory-tagging extensions for security, and connects to off-chip DRAM. Like the NI-700, it includes a high-throughput NoC and incorporates QoS mechanisms. The new unified interconnect reduces latency (performance), leakage current (power), and area compared with its predecessor. Arm states its SLC RAMs have 71% less leakage than standard compiled memories, which could be an oblique criticism of some RISC-V offerings.
The Lumex MMU L1 is Arm’s new system MMU (SMMU), which provides address translation and memory protection for all SoC blocks. The L1’s major change is a redesign of its translation buffer unit (TBU). Instantiated once for each SoC block (and thus replicated many times per chip), a TBU translates addresses using a local TLB. Incorporating a larger TLB, the new TBU has a better hit rate, which can reduce latency by up to 83%. At the same time, power can be up to 56% lower, and area (excluding the sizable RAMs) can be 38% smaller.
CSS Stays Central
To raise the value it delivers to licensees, last year, Arm began offering hard macros (physical IP) to licensees developing client chips. To craft a hardened instance, which Arm calls a compute subsystem (CSS), Arm integrates multiple blocks—including CPU cores, a GPU, and fast caches—and completes the back-end design. Customers have less work to finish their chips and should find that the CSS delivers better power, performance, and area than they could achieve by handling the back end themselves. The exemplary first-generation Lumex CSS platform targets a 3 nm process and comprises an eight-core CPU cluster with two C1 Ultras and six C1 Pros, a 14-core Mali G1-Ultra, and the new system IP.
Competition
Arm maintains an annual mobile-IP cadence to support yearly smartphone refreshes that keep revenue rolling in. The company has no rival to steal share from; saturated, the smartphone market has no need for new technology to drive adoption. Apple and Qualcomm employ their own designs. They are unlikely to switch to Arm’s IP, but they provide reference points. Arm supplies competitive, if not leading, CPUs and GPUs, enabling established companies (such as MediaTek) and new ones (such as Xiaomi) to deliver smartphone chips that perform like the well-funded behemoths’ all-proprietary designs.
Bottom Line
Arm has inaugurated its Lumex brand with upgrades throughout its mobile platform. The Lumex CPUs gain matrix extensions, and the little tier (Nano) gets a new microarchitecture with a decoupled front end. Mali’s ray-tracing acceleration doubles in performance, and system blocks are all-new designs.
CPU Conclusions
Several years ago, we were concerned that the Cortex-X family had too few customers to be a sustainable business. While Arm has lost Qualcomm as a licensee, it has picked up other customers, such as Xiaomi. Meanwhile, Cortex-X underpins Neoverse V cores, which are gaining additional licensees. Having become essential to Arm-based flagship smartphone chips, the microarchitecture is now available in a reduced configuration for sub-flagship designs as well.
At the other end of the mobile-CPU spectrum, Arm’s little cores had infrequent updates. Klein (Cortex-A510) wasn’t so little, necessitating the redesigned Hayes (Cortex-A520) core. Its replacement, the C1-Nano, has a slightly greater performance-to-area ratio and much better power efficiency. All-big-core flagship smartphone processors are here to stay, but the bulk of the market will benefit from an updated little core.
SME2 Conclusions
Importantly, the Nano supports SME2 with practically no impact on its size because Arm has centralized SME2 units instead of distributing copies to each CPU. While SME2 lacks the performance to replace an NPU or GPU for big AI and CV functions, it’s accessible from high-level frameworks and easier to program in C or assembly than an offload engine. Therefore, it will facilitate applications adding AI functions.
Arm has done a remarkable job enabling SME2. By creating Kleidi and integrating it with frameworks in advance of SME2’s availability, Arm broke the deadlock between developers requiring an installed base before coding for a hardware feature and chipmakers/OEMs requiring software support before adopting a new technology. End users will benefit from SME2 as soon as smartphones based on Lumex C1 are available.
GPU Conclusions
Ray tracing, however, exhibits signs of this deadlock. Accelerated in Arm’s flagship configurations—but not found lower in the product stack—it’s yet to become pervasive in smartphones. Games don’t broadly employ it because developers focus on gameplay for all users. Despite the prevalence of mobile gaming, PCs and consoles set the standard for graphics features. Arm, therefore, may wait to proliferate ray-tracing acceleration until it is more widely demanded.
Final Words
Arm has shown a remarkable commitment to annual refreshes. Although it hasn’t made significant changes to its top-end (Ultra), midrange (Pro), and GPU microarchitectures in a few years, it continually squeezes out performance and power improvements and occasionally rolls out substantial updates, such as SME2 and accelerated BVH traversal. Even as it has broadened its product line, it has kept up this pace. The PC market doesn’t move this fast, and we look forward to seeing Arm’s Niva lineup.