
Groq was one of many companies to realize that GPUs suboptimally execute neural networks. But like other NPU companies, it also failed to anticipate how AI models were changing. Groq’s technical shortcomings, along with the software and other challenges NPU startups face, diminished its products’ appeal to most customers. In a reversal, the strength-weakness duality of Groq’s architecture has proven complementary to GPUs, leading to Nvidia’s adoption.
How Will Nvidia Integrate Groq?
Nvidia recently licensed Groq’s technology and hired its key staff, avoiding a formal acquisition but leaving a lifeless husk of a corporate entity. At Nvidia’s recent GTC event, the company disclosed a forthcoming LPX system integrating Groq’s LP30 chip and a follow-on using a future LP35 design that supports four-bit floating-point data. The company positions the LPX for customers demanding greater per-user token throughput on large language models (LLMs) without sacrificing overall throughput. Furthermore, the Groq chips don’t employ scarce and costly HBM or even standard DRAM. Instead, they rely on internal SRAM, loaded by a PCIe-connected host.
Accessing SRAM is far faster than HBM or DRAM, eliminating a token-generation bottleneck. However, although a Groq NPU (which the company calls a tensor streaming processor or an LPU) has more SRAM than some chips, it’s insufficient for current-day LLMs, which are massive neural networks with large KV caches holding context.
Why Did Groq Eschew HBM and Conventional DRAM?
Groq’s founding era explains how the company designed an AI chip with such a fundamental shortcoming. Former Google engineers started Groq in 2016, a year before the “Attention is All You Need” paper and the transformer approach it described reshaped neural networks. Four years later, the company disclosed its architecture. In the early 2020s, the exemplary LLM was Bert, which had 110 million parameters. The entire Bert network could fit comfortably in a single eight-LPU Groq node. The company presented its first design at Hot Chips in August 2022. Three months later, ChatGPT showed the value of scaling up LLMs, rendering Bert irrelevant. Today, models can have 10,000 × as many parameters as Bert.
Why Divide LLMs Between XPU Types?
Groq systems can serve large models, but doing so requires multiple racks to handle what a single GPU-based card can do. On the other hand, the latency between tokens is much shorter with Groq’s technology. Pairing the two chip types, however, achieves a desirable middle ground when executing an LLM.
Called prefill, the first LLM stage processes a user’s prompt, computing input tokens’ embedding vectors in parallel in a single forward pass. To offload this compute-bound stage, Nvidia introduced Rubin CPX last year. Likely based on the company’s RTX family—the GPUs that actually process graphics in PCs and workstations—Rubin CPX’s big advantage over a data-center GPU was that it employs GDDR memory instead of the expensive and supply-constrained HBM. However, Rubin CPX disappeared from Nvidia’s roadmaps presented at the most recent GTC event.
The subsequent decode stage sequentially generates output tokens, conditioning each one on the previous tokens. Each output token, therefore, must pass through the model before the next can proceed. Furthermore, processing must access memory holding the vectors representing past tokens, the KV cache. Consequently, decoding is memory-bound.
However, decoding isn’t a single operation but comprises attention operations and feed-forward networks (FFNs). The attention mechanism here is similar to the ones that dominate prefill and requires access to the KV cache. An FFN is the stereotypical neural network depicted as rows of nodes connected to the nodes in adjacent rows. Processing FFNs is compute bound and time consuming. However, it does not require accessing the KV cache or other large structures, suiting the operation to Groq NPUs.
Developing a Better NPU Architecture
The Groq team’s key realization was that AI models are amenable to static analysis and deterministic execution. A compiler can examine a model and map it to processor functions, associating execution steps with specific hardware for every clock tick. However, processor state and behavior must be under the complete control of the compiler, necessitating in-order instruction execution and direct memory access. Techniques such as out-of-order execution and caching let the machine alter state without the compiler’s knowledge and must be avoided.
Eliminating those functions also simplifies Groq’s design. Groq breaks its architecture into four function-unit types (three execution units plus memory):
- MXM for matrix operations
- SXM for data manipulation
- VXM for vector operations
- MEM (memory) for storing data.
Conspicuously absent is a branch unit. Neural networks aren’t algorithms containing if-then constructs but instead are sequences of mathematical operations, which is exactly why Groq’s compiler can statically map them to hardware resources. A load/store unit isn’t listed either, but data, of course, must enter and exit the chip; the SXM handles I/O to/from chip-to-chip I/O units and the PCIe port to the host.
Operating on 16 INT8 (or FP8 in the LP30) values at a time, each execution unit is like a SIMD engine in a CPU. Pairing adjacent eight-bit lanes enables FP16 support. Laid out in an east-west (left-right) line, each unit passes its output to another unit in the same row over a ring-bus-like structure with a station (register) at each unit. Simplifying the design, no arbiters or queues manage bus access. Therefore, the compiler can compute a priori when a unit should access the bus and how many hops data will make traveling to its destination.
Tearing Through Feed-Forward Networks
Because each superlane can concurrently access its memory units, the chip’s aggregate memory bandwidth is massive: seven times that of the Nvidia Rubin GPU. A Groq processor can rip through an FFN because it only loads weights once before streaming in tokens and streaming out results.
Groq replicates the 16 × 8-bit superlanes on its chips, creating vertical MXM, SXM, VXM, and MEM stripes. Further simplifying the design, data mostly flows east and west. Only the SXM can move data north or south, from one superlane to another. The superlanes all execute the same operations, dispatched by a single instruction-control unit (ICU) at the bottom of the chip. However, their execution is skewed by a cycle relative to the superlane below it, which takes a cycle to latch an incoming operation and propagate it to the one above.
Thus, while each block within a superlane is a SIMD unit, it’s also part of a larger SIMD unit formed by the corresponding blocks in the other superlanes. Because the various function units receive operations in parallel, the group of operations forms a VLIW instruction bundle. In summary, a Groq NPU is a massive VLIW SIMD processor, as Figure 1 depicts. (Most LP30 pictures show the chip rotated 90 degrees, but we have maintained the orientation of Groq’s earlier disclosures.)

Addressing the Best-Paying Customers
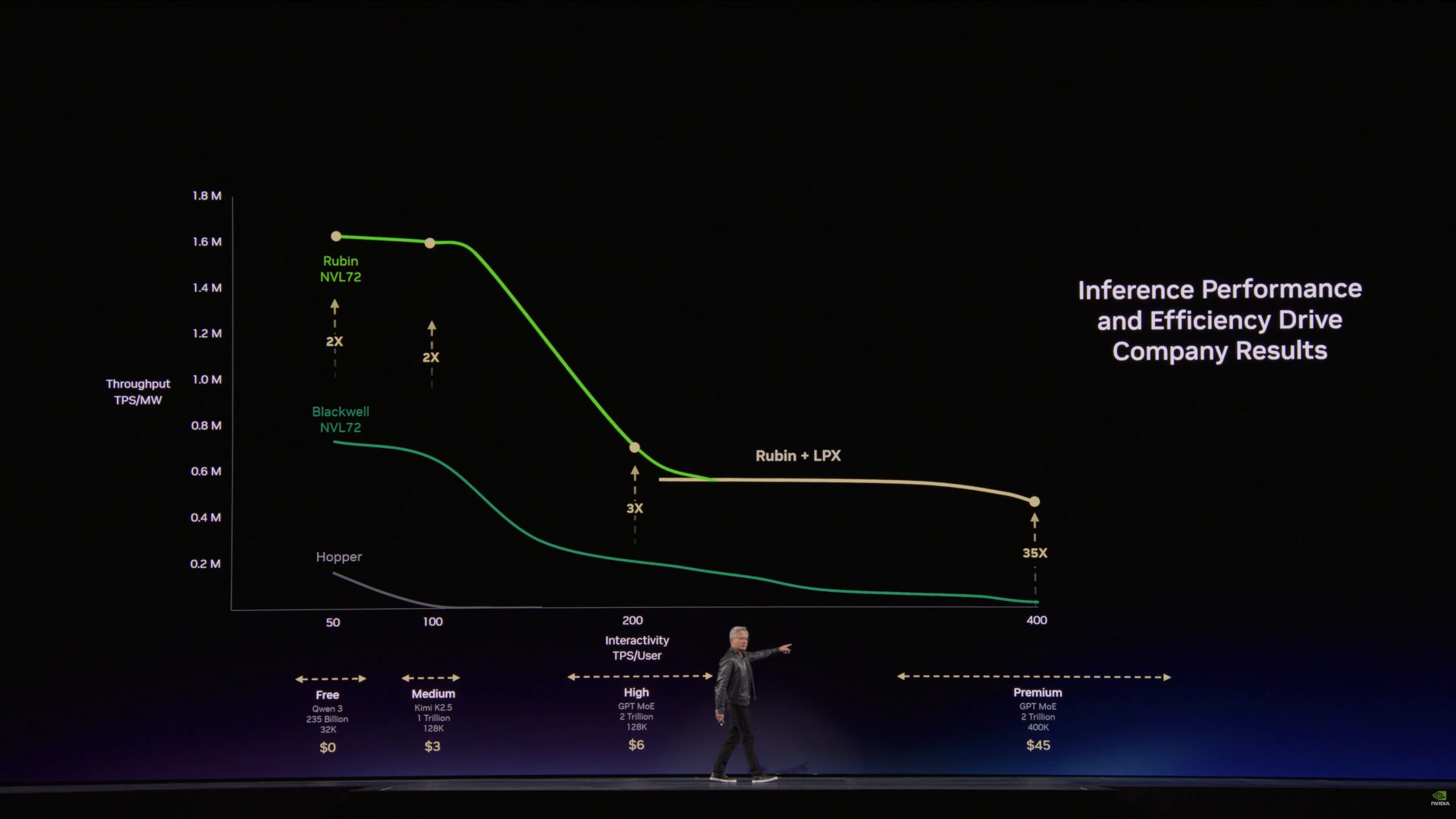
Nvidia asserts that AI companies serve multiple customer segments, including premium and “ultra” (above premium) tiers that pay the highest monthly subscription fees to obtain the fastest per-user token rates. While GPU-only systems can deliver the required rates for premium customers, the per-chip throughput of all users together is unacceptably low.
Joining its newest Rubin GPU with Groq’s technology in its new LPX systems, Nvidia delivers both high per-user rates and high aggregate throughput per watt, as Figure 2 shows. Moreover, the Rubin-LPX combination can support ultra customers paying triple the premium tier’s fees to obtain 1,000 tokens per second per user. Meanwhile, all-GPU clusters can continue to serve lower-tier customers, employing batching and other techniques to achieve the same or better aggregate throughput as an LPU-GPU combination but at lower per-user token rates.
Bottom Line
Groq’s LPU has come full circle. Its architecture promised performance but was unable to compete once LLMs dominated the AI landscape. Decomposing LLMs and distributing processing among different chip types, however, creates a new opportunity for the technology. Seeing a means to enable its customers to increase their revenue, Nvidia acquired Groq’s technology and inaugurated the era of heterogeneous AI processing.